

“问卷数据堆了 300 条,不知道用啥方法分析;跑了回归结果不对,却找不出哪里错了”—— 这是无数科研新手在数据环节的 “卡壳时刻”。而Paperzz 数据分析功能的出现,正在把 “数据分析” 从 “专业门槛” 变成 “一键操作”,让没学过 SPSS、Python 的普通人,也能把 “零散数据” 做成 “能支撑论文的实证结论”。
官网地址: https://www.paperzz.cc/dataAnalysis
一、Paperzz 数据分析:不是 “数据造假”,是 “科研小白的数据分析翻译机”
一提到 “AI 做数据分析”,很多人会担心 “是不是帮着编数据?” 但 Paperzz 的逻辑,是做 “数据分析的翻译机” 而非 “数据造假工具”:它不生成假数据,而是帮你 “选对方法、理清逻辑、可视化结果”—— 这恰恰是科研新手最缺的 “数据处理能力”。
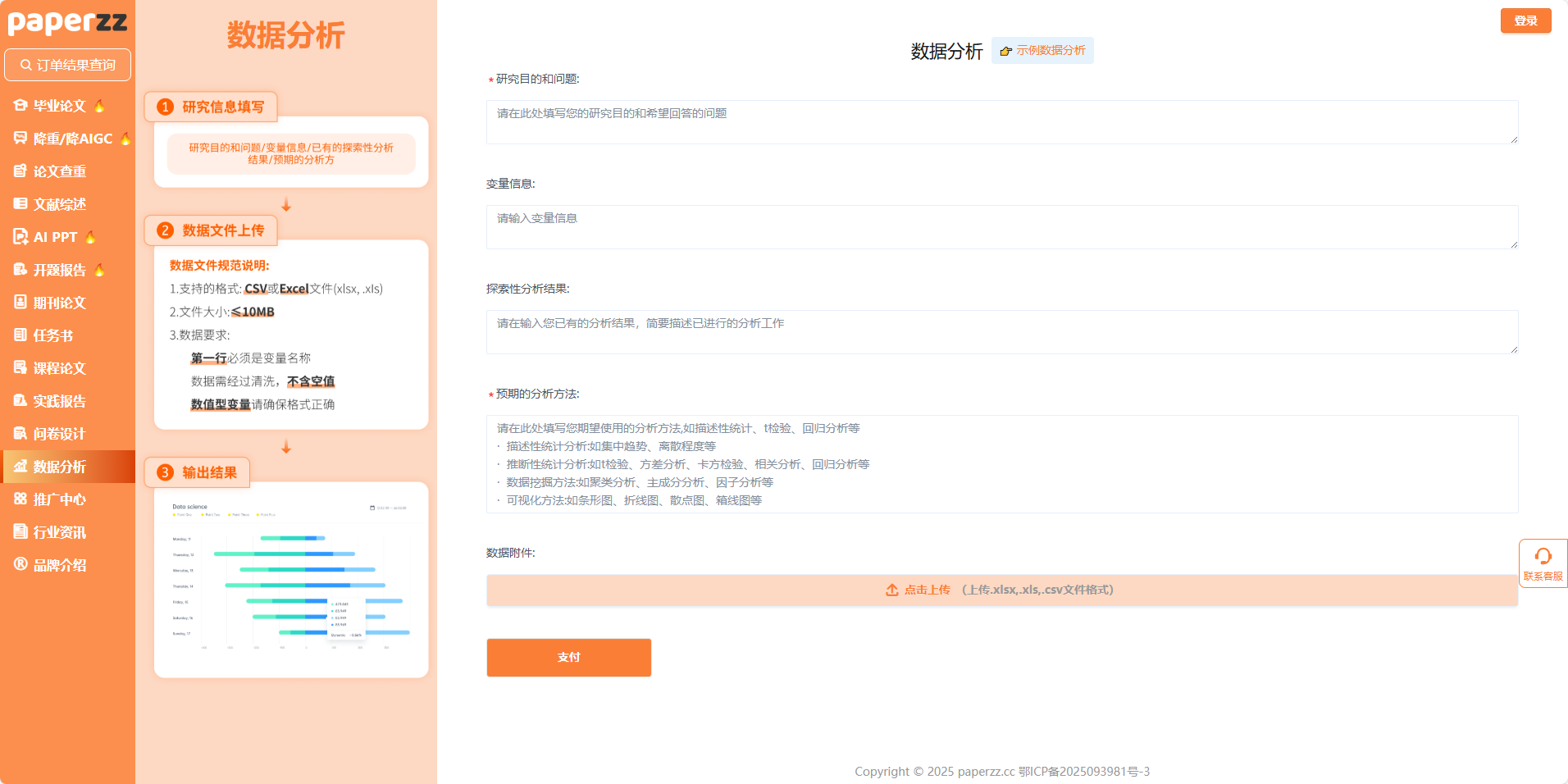
打开 Paperzz 的数据分析模块,你会看到清晰的三步流程:填研究信息→传数据文件→出分析结果。和传统 “对着软件说明书瞎点” 不同,这里的每一步都在帮你 “对齐科研逻辑”:
- 填 “研究目的和问题” 时,哪怕只写 “想看看性别对消费意愿的影响”,系统会自动提示 “建议补充‘年龄、收入’等控制变量”;
- 传数据文件前,系统会明确 “格式要求(CSV/Excel,不超过 10MB)”“数据规范(第一行是变量名、不能有空值)”,甚至帮你 “预清洗数据”—— 比如自动剔除 “年龄填 100 岁” 的异常值;
- 最关键的是 “预期分析方法” 模块:系统会列出 “描述性统计、t 检验、回归分析” 等方法的适用场景,你选 “回归分析” 后,会弹出 “该方法需要‘自变量 - 因变量’对应关系,请确认变量类型” 的提示 —— 相当于把 “统计学教材” 拆成了 “傻瓜式步骤”。
二、Paperzz 数据分析的 “四大反套路能力”:让数据不再 “拖论文后腿”
科研新手做数据分析,最容易犯 “方法选错、结果乱套、可视化丑” 的错 —— 而 Paperzz 的四个核心能力,刚好把这些 “坑” 都填上了。
能力 1:“方法智能匹配”,避免 “用 t 检验分析相关性”
很多人拿到数据,第一反应是 “随便选个方法跑跑看”—— 结果要么 “方法和问题不匹配”,要么 “结果无法解释”。Paperzz 的 “研究信息填写” 模块,相当于 “数据分析的‘方法导航’”。
比如你填 “研究目的:分析不同学历对线上购物频率的影响”,系统会自动推荐 “单因素方差分析(ANOVA)”,并解释 “该方法适用于‘分类自变量(学历)→连续因变量(购物频率)’的差异分析”;若你填 “研究目的:看消费意愿和收入的关系”,系统会推荐 “Pearson 相关分析 + 线性回归”,还会提示 “回归前需要做‘多重共线性检验’”。
有用户分享:“之前我想用 t 检验分析‘三个年龄段的差异’,Paperzz 提示‘t 检验只适用于两组对比,建议用方差分析’—— 要是没这个提示,论文里的方法错误直接会被导师打回。”
能力 2:“数据预清洗 + 异常值提醒”,不让 “脏数据毁了结论”
科研中,“脏数据”(比如空值、异常值)是结论错误的 “隐形杀手”—— 而 Paperzz 在你传数据时,就帮你把 “脏数据” 筛出来了。
上传 Excel 文件后,系统会先做 “数据校验”:若你的 “收入” 变量里有 “0 元”“10 万元” 的极端值,会弹出 “发现 2 个异常值,是否剔除?”;若有 “性别” 变量填 “男 / 女 / 未知”,会提示 “‘未知’样本占比 10%,建议补充或说明”。甚至,系统会帮你 “自动编码分类变量”—— 比如把 “性别:男 / 女” 转换成 “1/0”,方便后续做回归分析。
这相当于在 “跑分析前”,先帮你把 “数据的地基” 打牢了 —— 不用再等跑出来 “荒谬结果”,才回头找 “是不是数据错了”。
能力 3:“结果自动解读”,把 “系数表” 变成 “人话结论”
很多人跑出来回归结果,看着 “系数 0.23、P 值 0.04”,不知道怎么写成 “论文里的结论”——Paperzz 的 “输出结果” 模块,直接帮你 “把统计结果翻译成学术语言”。
比如回归结果显示 “收入的系数是 0.3(P<0.05)”,系统会自动生成:“收入每增加 1 单位,消费意愿显著提升 0.3 单位(P=0.04<0.05),说明收入是影响消费意愿的正向显著因素”;若结果显示 “性别系数不显著(P=0.2)”,会提示 “性别对消费意愿的影响未通过显著性检验,可能需要补充样本量或调整控制变量”。
更贴心的是,系统会帮你 “标注结果的科研价值”:比如 “该结论与《2024 中国消费行为报告》的研究一致,进一步验证了收入的影响效应”—— 直接帮你把 “数据分析结果” 和 “文献脉络” 连起来。
能力 4:“可视化一键美化”,让图表从 “Excel 默认样式” 变 “期刊级审美”
很多论文里的图表,要么是 “Excel 默认的丑表格”,要么是 “字体模糊、标签不全”—— 而 Paperzz 的 “输出结果”,直接生成 “期刊级可视化图表”。
比如做 “描述性统计”,会自动生成 “带误差线的柱状图”(展示不同群体的均值差异);做 “回归分析”,会生成 “系数森林图”(清晰展示各变量的显著性);甚至,图表会自动匹配 “学术规范”:字体是 “宋体 / Times New Roman”,标签是 “变量名 + 单位”,图例放在 “图表右侧”—— 不用再手动调整 “柱形颜色、坐标轴刻度”,直接复制到论文里就能用。
三、Paperzz 数据分析:是 “工具”,更是 “科研思维的启蒙课”
有人会说:“用 AI 做分析,会不会学不会统计学?” 但实际体验后会发现,Paperzz 更像 “科研思维的启蒙课”—— 它教你的是 “数据和研究的对应关系”,而不是 “替你学统计”。
比如,你选 “回归分析” 后,系统会弹出 “自变量不能和因变量高度相关,请先做相关性检验” 的提示 —— 这其实是在教你 “如何避免多重共线性”;生成结果后,会标注 “该方法的局限性:无法证明因果关系,只能说明相关性”—— 这是在教你 “如何客观解释结果”。
甚至,它能帮你 “补全科研逻辑”:比如你只传了 “消费意愿” 的问卷数据,系统会提示 “建议补充‘实际消费行为’的客观数据,让结论更有说服力”—— 这恰恰是导师会追问的 “数据说服力” 问题。
四、科研新手亲测:用 Paperzz 数据分析,3 小时搞定 “别人 3 天的活”
某二本院校的社会学本科生小张,做 “大学生短视频使用时长与学习成绩的关系” 的论文,原本计划用 3 天处理 200 份问卷数据,结果用 Paperzz 只花了 3 小时:“我传了 Excel 数据,系统先帮我清了 5 个空值;选了‘Pearson 相关 + 线性回归’,结果显示‘使用时长和成绩的相关系数是 - 0.25(P<0.01)’,系统还自动生成了‘负向显著’的结论和散点图。导师看了说‘数据处理逻辑没问题,直接放到论文里就行’—— 要是自己学 SPSS,至少得折腾一周。”
对科研新手来说,“数据分析难” 的本质是 “没摸清‘数据 - 方法 - 结论’的逻辑”—— 而 Paperzz 的价值,就是把这个 “逻辑” 拆成了 “可操作的步骤”,让你能把精力放在 “研究问题本身”,而不是 “和软件较劲”。
毕竟,科研的核心是 “回答问题”,而不是 “证明自己会用软件”。当 Paperzz 把 “数据分析的门槛” 降低,你只需要专注于 “问对问题、收对数据”—— 这才是科研的 “正确打开方式”。